
壁纸娘发的图片真好看啊,不如……
爬虫需要遵循Robots协议
一般爬虫类型
一般分为两类
1.服务端渲染的页面(ssr)
在服务端生成DOM树,即可以右键查看源代码,可以看到完整html片段
这个时候可以使用cherrio+axios进行爬虫
2.客户端渲染的页面(csr)
在客户端生成DOM树,右键查看源代码是看不到的有用信息
这个时候需要分析接口
而b站就是属于第二种
分析流程
找到返回壁纸的接口
通过访问接口,返回批量壁纸下载链接
下载壁纸
准备
目录
|--img | | |--index.js
安装依赖
axios请求库
npm i axios
开始
1.找到返回壁纸的接口

2.通过访问接口,返回批量壁纸下载链接
可以看到图片的src在data对象中,通过遍历就可以获取所有下载链接
//分析页面
async function parsePage(uid, num) {
try {
const downUrlArr = []
const downNameArr = []
for (let i = 0; i <= num; i++) {
//接口地址
let pageUrl = "https://api.vc.bilibili.com/link_draw/v1/doc/doc_list?uid=" + uid + "&page_num=" + i +
"&page_size=30&biz=all"
const res = await axios.get(pageUrl)
res.data.data.items.forEach((item) => {
let title = item.doc_id
let imgUrlArr = item.pictures
let imgUrl = imgUrlArr[0].img_src
//存入数组
downUrlArr.push(imgUrl)
downNameArr.push(title)
});
}
//打印出下载链接
console.log(downUrlArr)
//下载图片
downImgs(downUrlArr, downNameArr)
return Promise.resolve()
} catch (err) {
return Promise.reject(err)
}
}3.下载壁纸
async function downImg(imgUrl, index) {
try {
//图片路径
let pathname = path.resolve(__dirname, `./img/${imgUrl.split('/').pop()}`);
// console.log(pathname)
//创建图片写入流
const res = await axios.get(imgUrl, {
responseType: 'stream'
})
let ws = fs.createWriteStream(pathname)
await res.data.pipe(ws);
await res.data.on('close', function() {
ws.close()
console.log(`第${index}张写入完成`);
})
return Promise.resolve()
} catch (err) {
console.log('写入失败')
return Promise.reject(err)
}
}运行
完整代码
const axios = require('axios')
const fs = require('fs')
//分析页面
async function parsePage(uid,num){
try {
//接口地址
let pageUrl= "https://api.vc.bilibili.com/link_draw/v1/doc/doc_list?uid="+uid+"&page_num=" + num + "&page_size=30&biz=all"
const downUrlArr = []
const downNameArr = []
let res = await axios.get(pageUrl)
res.data.data.items.forEach((item) => {
let title = item.doc_id
let imgUrlArr = item.pictures
let imgUrl = imgUrlArr[0].img_src
//存入数组
downUrlArr.push(imgUrl)
downNameArr.push(title)
});
// //下载图片
downImgs(downUrlArr,downNameArr)
return Promise.resolve()
}catch(err){
return Promise.reject(err)
}
}
//下载图片
async function downImgs(imgUrlArr,downNameArr){
try {
for(let i=0 ; i<imgUrlArr.length ; i++){
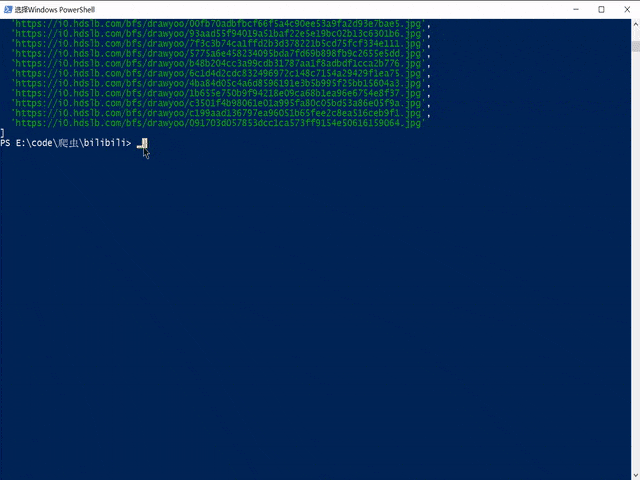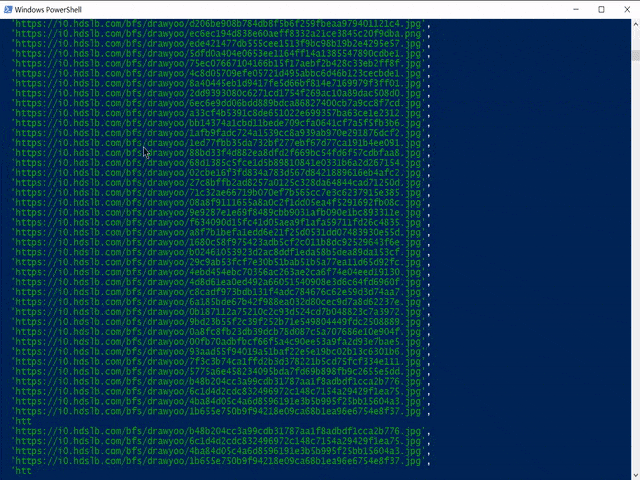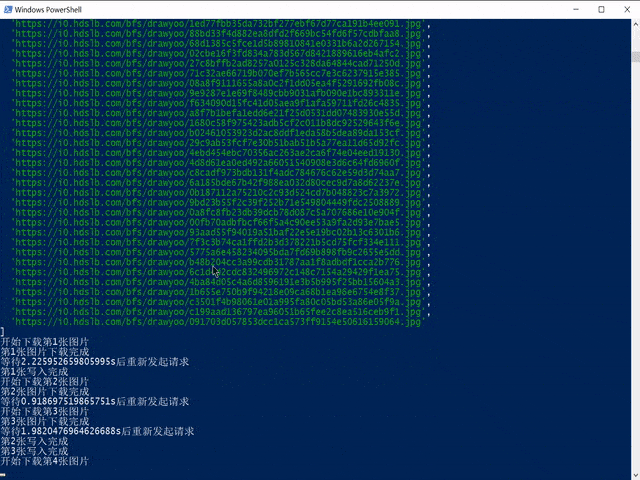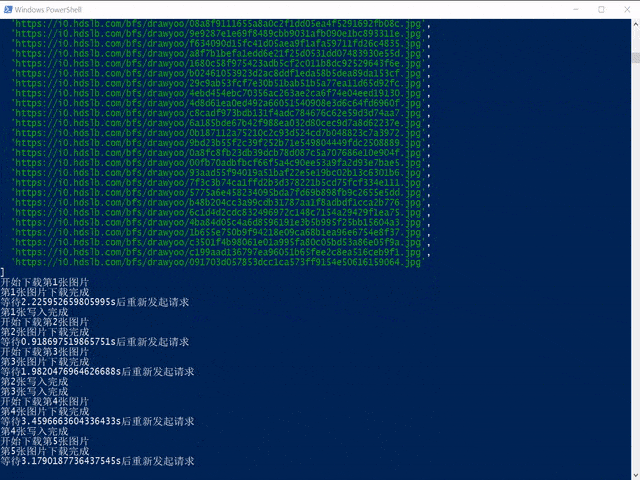
console.log(`开始下载第${i+1}张图片`)
await downImg(imgUrlArr[i],downNameArr[i])
console.log(`第${i+1}张图片下载完成`)
await wait(5000*Math.random())
}
return Promise.resolve()
}catch(err){
console.log('写入失败')
return Promise.reject(err)
}
}
//下载图片
async function downImg(imgUrl){
try{
//图片路径
let pathname = `./img/${imgUrl.split('/').pop()}`
// console.log(pathname)
//创建图片写入流
const res = await axios.get(imgUrl,{responseType:'stream'})
await res.data.pipe(fs.createWriteStream(pathname));
console.log('写入成功');
return Promise.resolve()
}catch(err){
console.log('写入失败')
return Promise.reject(err)
}
}
//设置等待时间--防封
async function wait(times){
return new Promise((reslove) => {
console.log(`等待${times/1000}s后重新发起请求`)
setTimeout(() => {
reslove()
},times)
})
}
//开始爬取
async function spider(uid,num){
//uid B站uid,
//num 爬取页面数
for(let i=0 ; i<=num ; i++){
parsePage(uid,i)
}
}
spider(6823116,3)
ps:哔哩哔哩爬虫协议 没有不允许/album/目录